Решения для обеспечения отказоустойчивости
Содержание:
- Методы повышения надежности ИТ-инфраструктуры
- Резервное копирование данных: основные подходы
- Автоматическое переключение на резервные серверы
- Использование кластерных технологий для устойчивости
- Роль облачных сервисов в отказоустойчивости
- Мониторинг и предсказание сбоев систем
- Вопрос-ответ

Для создания более надежной инфраструктуры требуется учитывать множество факторов. Первостепенное значение имеет проектирование и реализация таких подходов, которые минимизируют вероятность поломок и потерь данных. В этом контексте речь пойдет о стратегиях, которые позволяют системе продолжать работу даже при наличии непредвиденных обстоятельств. Рассмотрим, какие технологии и методыпомогут в этом, и как их правильно применять на практике.
Переход к более устойчивой архитектуре требует внимательного анализа и выбора подходящих инструментов. Независимо от масштаба и специфики бизнеса, важно учитывать все аспекты, начиная от аппаратного обеспечения и заканчивая программными решениями. Внедрение этих принципов позволяет повысить надежностьи защитить систему от различных угроз, что в конечном итоге способствует стабильности и эффективности работы организации.
Методы повышения надежности ИТ-инфраструктуры
1. Резервирование компонентов
Одним из самых эффективных методов является резервирование. Включение дублирующих элементов в ИТ-инфраструктуру, таких как серверы, сети и источники питания, позволит избежать полного отключения системы в случае отказа какого-либо компонента. Данный подход существенно повышает общую надежность, так как любая неисправность будет быстро устранена за счет включения резервного элемента.

2. Виртуализация ресурсов
Виртуализация предоставляет возможность более гибкого управления ресурсами и повышения их использования. Это решение позволяет изолировать различные приложения и сервисы друг от друга, что снижает риск распространения проблем. В случае необходимости миграция виртуальных машин на другой физический сервер будет произведена быстро и без простоев для конечных пользователей.
3. Регулярное обновление и мониторинг
Систематическое обновление программного обеспечения и оборудования, а также постоянный мониторинг состояния системы, позволяют своевременно выявлять и устранять потенциальные угрозы. Применение автоматизированных систем мониторинга и оповещения позволит вам заранее узнать о возможных проблемах и предпринять необходимые меры для их предотвращения.
4. Управление данными и резервное копирование
Надежное управление данными и регулярное резервное копирование являются ключевыми элементами. Создание копий данных на различных носителях и в разных географических локациях гарантирует их сохранность даже в случае серьезных инцидентов. Это позволит быстро восстановить систему и минимизировать потери информации.
5. Тестирование и планирование аварийного восстановления
Регулярное тестирование процедур аварийного восстановления и составление подробных планов на случай непредвиденных ситуаций помогут подготовиться к возможным инцидентам. Включение сценариев тестирования и их регулярное обновление позволит сделать систему более готовой к различным видам сбоев и оперативно восстановить её функциональность.
Использование вышеупомянутых методов и стратегий позволит сделать ИТ-инфраструктуру вашей организации более надежной, сократить время простоя и обеспечить стабильную работу всех систем и приложений.
Резервное копирование данных: основные подходы
- Полное резервное копирование: Этот метод предполагает создание копии всех данных системы. Это наиболее надёжный способ, так как он позволяет восстановить всю систему целиком. Однако он требует значительных ресурсов, как по времени, так и по объёму хранилища.
- Дифференциальное резервное копирование: В этом случае создаются копии только тех данных, которые изменились с момента последнего полного резервного копирования. Такой подход более эффективен по времени и объёму хранилища по сравнению с полным копированием, но требует регулярного выполнения полного резервного копирования для поддержания актуальности данных.
- Инкрементное резервное копирование: Данный метод сохраняет только те данные, которые были изменены с последнего резервного копирования, будь то полное или инкрементное. Это позволяет экономить время и место для хранения, но процесс восстановления может быть более сложным и длительным, так как потребуется последовательно восстанавливать данные из всех предыдущих копий.
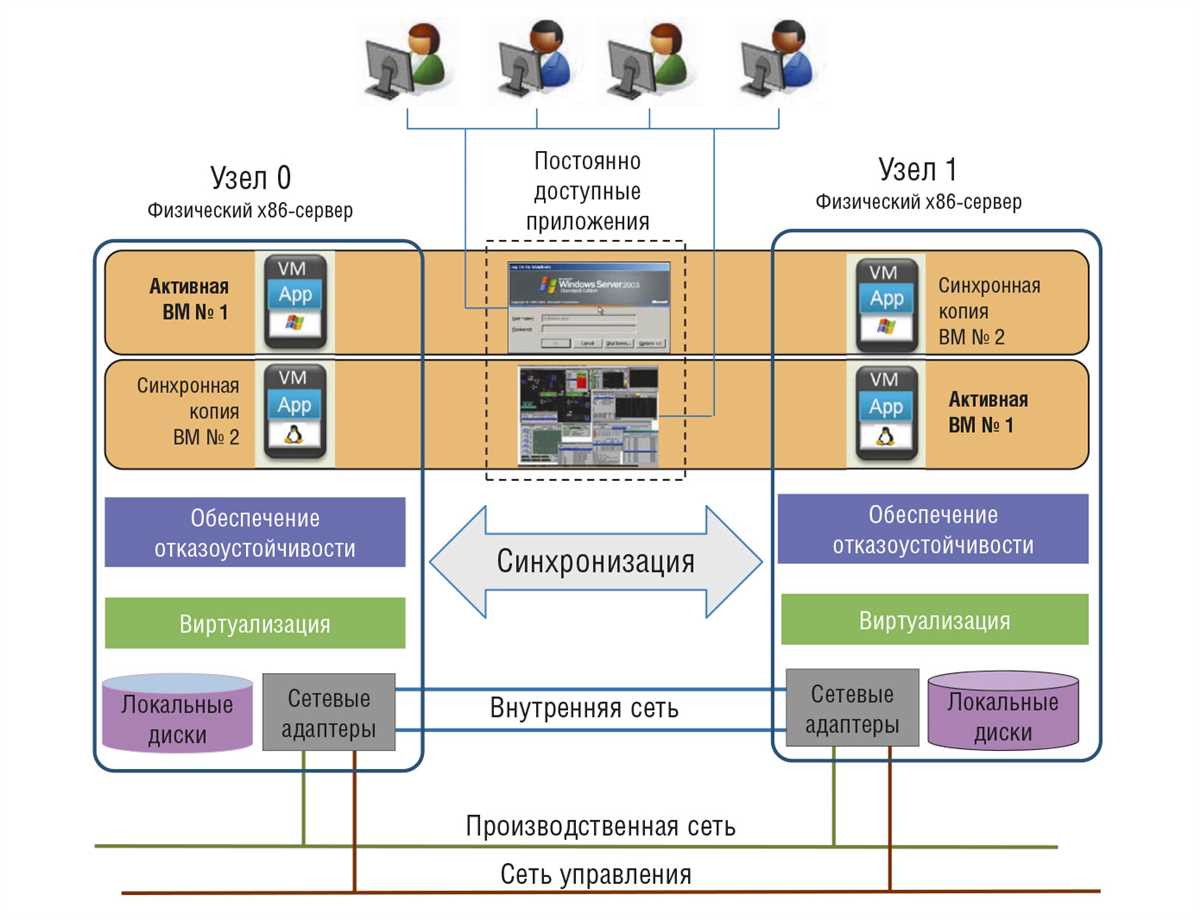
Каждый из перечисленных методов имеет свои преимущества и недостатки. Выбор конкретного подхода зависит от требований к системе, доступных ресурсов и объёма данных. Использование нескольких методов в сочетании может дать наилучший результат, позволив создать комплексную систему защиты данных, которая будет более гибкой и надёжной.
Кроме того, важным аспектом является регулярное тестирование резервных копий. Это позволит убедиться в их актуальности и работоспособности, что особенно важно для критически важных данных. Современные решения предлагают автоматизацию этого процесса, что значительно упрощает задачу и позволяет вовремя обнаружить возможные проблемы.
Независимо от выбранного метода, главная цель резервного копирования – обеспечение доступности данных и минимизация потерь при любых непредвиденных обстоятельствах. Грамотно организованное резервное копирование – это залог стабильной работы любой информационной системы.
Автоматическое переключение на резервные серверы
Когда основной сервер выходит из строя, система автоматически переключается на резервный сервер. Это позволяет пользователям продолжать работу без заметных задержек. Такой подход особенно полезен для крупных предприятий, где даже кратковременный простой может привести к значительным убыткам. Важно отметить, что автоматизация данного процесса делает его более эффективным и снижает человеческий фактор в критические моменты.
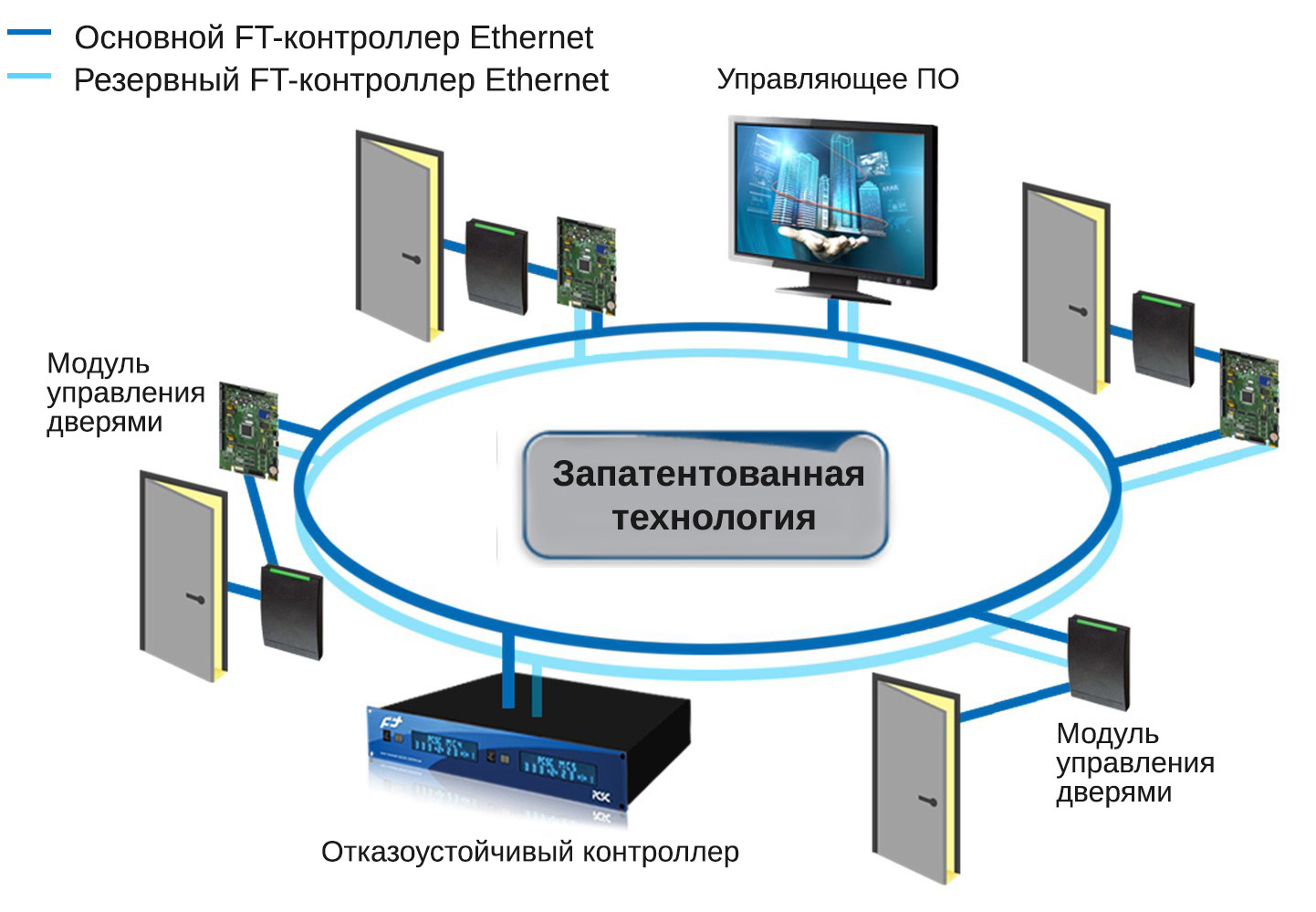
Каким образом можно сделать это решение максимально эффективным? Во-первых, необходимо правильно настроить мониторинг основной системы, чтобы своевременно обнаружить неисправности. Во-вторых, следует предусмотреть наличие нескольких резервных серверов, что позволит более гибко реагировать на различные виды сбоев. Наконец, регулярное тестирование и обновление резервных систем поможет поддерживать их в актуальном состоянии и готовности к любым неожиданным ситуациям.
Таким образом, автоматическое переключение на резервные серверы обеспечивает бесперебойную работу сервисов и минимизирует риски, связанные с непредвиденными сбоями. Это решение позволяет компаниям сохранять устойчивость и надежность своих IT-инфраструктур, что особенно важно в условиях постоянно растущих требований к качеству и скорости предоставляемых услуг.
Использование кластерных технологий для устойчивости
Современные информационные системы требуют высокой надежности и непрерывности работы. Один из подходов, который поможет добиться этих целей, заключается в применении кластерных технологий. Кластеры позволяют распределять нагрузку и обеспечивать работу даже при выходе из строя отдельных компонентов.
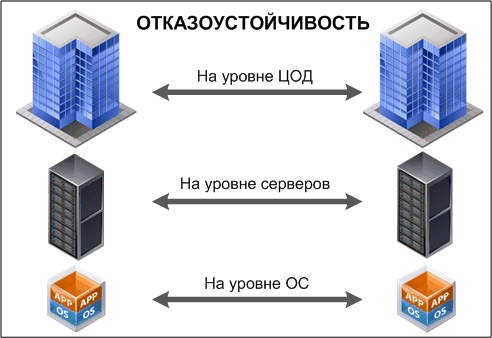
Кластеризация включает в себя объединение нескольких серверов в единое целое. Это позволяет более эффективно использовать ресурсы и создавать устойчивую к сбоям систему. В случае отказа одного из узлов, его функции автоматически берут на себя другие узлы кластера, что делает систему менее уязвимой к непредвиденным обстоятельствам.
Использование кластерных технологий обеспечивает значительное повышение производительности и надежности. Система становится более гибкой и управляемой, что позволяет легко масштабировать ресурсы в зависимости от текущих потребностей. Кластеры также способствуют улучшению распределения данных, обеспечивая их доступность и целостность.
Таким образом, внедрение кластерных технологий является ключевым фактором для создания устойчивой и надежной информационной инфраструктуры. Это позволит бизнесу минимизировать простои и обеспечить бесперебойную работу всех критически важных приложений.
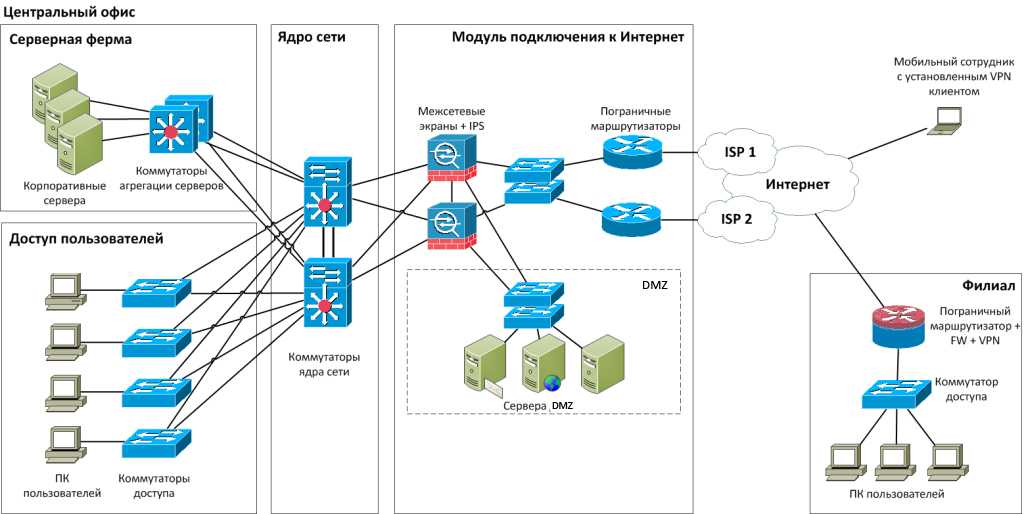
Роль облачных сервисов в отказоустойчивости
Одним из главных преимуществ облачных сервисов является их способность автоматически перераспределять ресурсы в случае аварии. Это позволяет системе продолжать функционировать, даже если отдельные компоненты выходят из строя. Благодаря этому, компании могут сделать свои приложения и услуги более надежными и доступными для пользователей.
Кроме того, использование облачных сервисов позволяет снизить затраты на поддержание резервной инфраструктуры. В традиционных системах создание и поддержка резервных копий требует значительных инвестиций. В облаке же это реализуется через распределенные дата-центры, что позволяет обеспечить надежное хранение данных и быстроту их восстановления.
С помощью облачных сервисов можно легко масштабировать ресурсы в зависимости от текущих потребностей. Это означает, что в периоды пиковых нагрузок система сможет автоматически задействовать дополнительные мощности, а в моменты снижения активности - уменьшить их. Такая гибкость делает инфраструктуру более устойчивой к различным нагрузкам и непредвиденным ситуациям.
Не менее важным является и вопрос безопасности. Облачные провайдеры предлагают комплексные решения для защиты данных, что позволяет минимизировать риски их утраты или повреждения. Система, построенная с использованием облачных технологий, будет более защищенной благодаря постоянному мониторингу и обновлению средств защиты.
Мониторинг и предсказание сбоев систем
Для поддержания надежности и бесперебойной работы современных информационных технологий необходимо внимательно следить за состоянием всех компонентов. Активное наблюдение и анализ данных позволяют своевременно выявлять потенциальные проблемы и предотвращать их до того, как они повлияют на функционирование всей инфраструктуры. Применение таких методов помогает сделать работу системы более стабильной и минимизировать риск неожиданных отключений.
Мониторинг системы включает в себя постоянное отслеживание ключевых показателей производительности и состояния оборудования. Это позволяет выявлять аномалии и быстро реагировать на возникающие трудности. Современные инструменты мониторинга предоставляют администраторам возможность собирать информацию из различных источников и визуализировать ее для более эффективного анализа.
Предсказание сбоев основывается на анализе исторических данных и применении алгоритмов машинного обучения. Это помогает выявить закономерности, которые предшествуют возникновению проблем, и заранее принять меры для их предотвращения. Внедрение таких методов дает возможность не только устранить текущие неполадки, но и значительно снизить вероятность их повторного появления в будущем.
Комплексный подход к мониторингу и предсказанию сбоев включает использование различных инструментов и технологий, таких как системы оповещения, аналитические платформы и автоматические скрипты. Эти средства позволяют администраторам более эффективно управлять инфраструктурой и минимизировать влияние сбоев на пользователей и бизнес-процессы.
Таким образом, применение мониторинга и предсказания сбоев позволяет сделать систему более устойчивой к внешним и внутренним воздействиям, обеспечивая непрерывность и стабильность работы. Такое решение требует внедрения современных технологий и постоянного совершенствования подходов к управлению и анализу данных.
Вопрос-ответ
Какие основные подходы используются для создания отказоустойчивых систем?
Для создания отказоустойчивых систем используются несколько основных подходов. Резервирование компонентов: включает дублирование ключевых компонентов системы, таких как серверы, сети и хранилища данных, чтобы обеспечить их доступность в случае сбоя. Кластеризация: разделение системы на несколько кластеров, каждый из которых может автоматически подхватить работу при выходе из строя другого кластера. Балансировка нагрузки: распределение входящих запросов и операций между несколькими серверами, что позволяет избежать перегрузки и равномерно распределить рабочую нагрузку. Горизонтальное масштабирование: увеличение количества одинаковых компонентов системы для распределения нагрузки и повышения надежности. Использование облачных технологий: облачные платформы предлагают множество инструментов и сервисов для обеспечения отказоустойчивости, включая автоматическое восстановление, резервное копирование и глобальное распределение данных. Эти подходы могут комбинироваться для достижения максимальной надежности и доступности системы.
Что такое балансировка нагрузки и как она улучшает отказоустойчивость системы?
Балансировка нагрузки – это процесс распределения входящих сетевых запросов и операций между несколькими серверами или узлами системы для оптимизации использования ресурсов и повышения производительности. Балансировка нагрузки улучшает отказоустойчивость системы следующими способами. Предотвращение перегрузки: балансировка помогает равномерно распределить нагрузку, предотвращая перегрузку отдельных серверов и снижая риск их выхода из строя. Автоматическое переключение: в случае сбоя одного из серверов, запросы автоматически перенаправляются на другие доступные серверы, обеспечивая непрерывность работы. Повышение производительности: за счет распределения нагрузки улучшается общая производительность системы, что также способствует ее стабильности и надежности. Гибкость масштабирования: балансировщики нагрузки позволяют легко добавлять новые серверы в систему, что обеспечивает возможность горизонтального масштабирования для поддержания отказоустойчивости при увеличении нагрузки. Таким образом, балансировка нагрузки является ключевым компонентом в архитектуре отказоустойчивых систем.
Какие преимущества предоставляет использование облачных технологий для отказоустойчивых решений?
Использование облачных технологий для отказоустойчивых решений предоставляет ряд значительных преимуществ. Автоматическое восстановление: облачные платформы предлагают автоматическое восстановление сервисов и данных в случае сбоя, минимизируя время простоя. Гибкость и масштабируемость: облачные решения позволяют быстро масштабировать ресурсы в зависимости от текущих потребностей, что способствует поддержанию стабильности и производительности системы. Глобальное распределение данных: облака обеспечивают хранение данных в различных географических регионах, что защищает от локальных сбоев и катастроф. Инструменты мониторинга и управления: облачные провайдеры предоставляют инструменты для мониторинга состояния системы, быстрого реагирования на инциденты и автоматического управления ресурсами. Экономическая эффективность: облачные решения позволяют оптимизировать затраты на инфраструктуру, так как оплата производится только за фактически используемые ресурсы, что уменьшает издержки на резервные мощности. Эти преимущества делают облачные технологии привлекательным выбором для создания отказоустойчивых систем.
Какой метод горизонтального масштабирования наиболее эффективен для обеспечения отказоустойчивости?
Наиболее эффективным методом горизонтального масштабирования для обеспечения отказоустойчивости является использование контейнеров и оркестраторов, таких как Kubernetes. Этот метод обеспечивает следующие преимущества: легкость развертывания и управления: Контейнеризация позволяет быстро разворачивать и управлять приложениями в различных средах без изменений в коде. Автоматическое восстановление: оркестраторы, такие как Kubernetes, автоматически отслеживают состояние контейнеров и перезапускают их в случае сбоя, обеспечивая непрерывность работы. Распределение нагрузки: оркестраторы эффективно распределяют нагрузку между контейнерами, что помогает избежать перегрузок и повышает отказоустойчивость. Горизонтальное масштабирование: контейнеры позволяют легко добавлять и удалять экземпляры приложений в зависимости от текущей нагрузки, обеспечивая гибкость и стабильность системы. Изоляция процессов: контейнеры обеспечивают изоляцию процессов, что минимизирует влияние одного компонента на другие при возникновении сбоев. Таким образом, использование контейнеров и оркестраторов является одним из наиболее эффективных методов горизонтального масштабирования для обеспечения отказоустойчивости систем.
Какие основные методы позволяют повысить отказоустойчивость системы?
Для повышения отказоустойчивости системы применяются несколько основных методов. Резервирование: включает дублирование критически важных компонентов системы. Это может быть аппаратное резервирование (например, использование нескольких серверов) или программное резервирование (например, дублирование баз данных). Балансировка нагрузки: этот метод распределяет рабочую нагрузку между несколькими серверами или узлами, что позволяет избежать перегрузки одного из них и минимизирует риск отказа. Кластеризация: объединение нескольких серверов в кластер, где каждый сервер может выполнять функции других серверов в случае их выхода из строя. Резервное копирование и восстановление: регулярное создание резервных копий данных и наличие четкого плана их восстановления в случае сбоя. Использование облачных технологий: облачные провайдеры часто предлагают встроенные решения для обеспечения высокой доступности и отказоустойчивости, такие как распределение данных по разным дата-центрам. Каждый из этих методов имеет свои преимущества и лучше всего работает в комбинации с другими, обеспечивая многоуровневую защиту и надежность системы.
Какое программное обеспечение лучше использовать для повышения отказоустойчивости веб-приложений?
Для повышения отказоустойчивости веб-приложений существует несколько популярных решений. NGINX и HAProxy: эти программные продукты используются для балансировки нагрузки и обеспечения высокой доступности. NGINX также может выполнять функции веб-сервера и обратного прокси, что делает его универсальным инструментом. Kubernetes: это оркестрационная платформа для контейнеров, которая помогает управлять распределенными приложениями и сервисами. Kubernetes обеспечивает автоматическое восстановление контейнеров, которые выходят из строя, и позволяет легко масштабировать приложения. Docker Swarm: еще одно решение для оркестрации контейнеров, которое обеспечивает отказоустойчивость через автоматическое распределение контейнеров по доступным узлам в кластере. Amazon Web Services (AWS): платформа AWS предлагает различные инструменты для повышения отказоустойчивости, такие как Amazon Elastic Load Balancing, Amazon RDS (для баз данных) и Amazon S3 (для хранения данных). Эти сервисы позволяют автоматически масштабировать и восстанавливать приложения в случае отказа. Microsoft Azure и Google Cloud Platform (GCP): эти облачные платформы также предоставляют множество инструментов для повышения отказоустойчивости, включая автоматическое масштабирование, балансировку нагрузки и управление базами данных. Выбор конкретного решения зависит от особенностей вашего веб-приложения, бюджета и технических требований. Важно также учитывать интеграцию этих решений с существующей инфраструктурой и возможность их гибкой настройки под ваши нужды.
Читайте также:
- Как создать отказоустойчивую сеть и обеспечить бесперебойную работу
- Настройка отказоустойчивого кластера для максимальной надежности и производительности
- Как создать отказоустойчивую инфраструктуру для вашего бизнеса
- Отказоустойчивое хранилище как ключ к стабильности данных
- Как создать отказоустойчивый компьютер