Как построить отказоустойчивый кластер для максимальной надежности
Содержание:
- Основные принципы отказоустойчивости
- Технологии для построения кластеров
- Обзор архитектурных решений
- Мониторинг и управление кластерами
- Резервное копирование и восстановление
- Преимущества отказоустойчивых серверов
- Вопрос-ответ

Одним из эффективных подходов к обеспечению надежности серверных систем является применение архитектур, способных сохранять работоспособность даже при выходе из строя отдельных компонентов. Такие архитектуры позволяют минимизировать риски простоев и обеспечивают высокую доступность сервисов. В данном разделе мы рассмотрим ключевые аспекты построения надежных серверных систем, а также обсудим основные принципы и технологии, которые используются для достижения высокой устойчивости к отказам.
Основная цель состоит в том, чтобы создать систему, способную автоматически и без потерь переключаться на резервные ресурсы при возникновении неполадок. Использование современных инструментов и подходов позволяет достичь необходимого уровня надежности и производительности. В следующей части статьи мы подробно разберем различные методики и стратегии, применяемые для построения таких систем, а также рассмотрим реальные примеры их использования в индустрии.
Основные принципы отказоустойчивости
В современном мире информационных технологий, обеспечение непрерывной работы серверных систем становится одной из ключевых задач. При проектировании распределённых вычислительных систем важно учитывать возможность возникновения сбоев и предпринимать меры для минимизации их последствий. В данном разделе мы рассмотрим базовые подходы и методы, которые позволяют системам продолжать работу, даже при возникновении непредвиденных проблем.
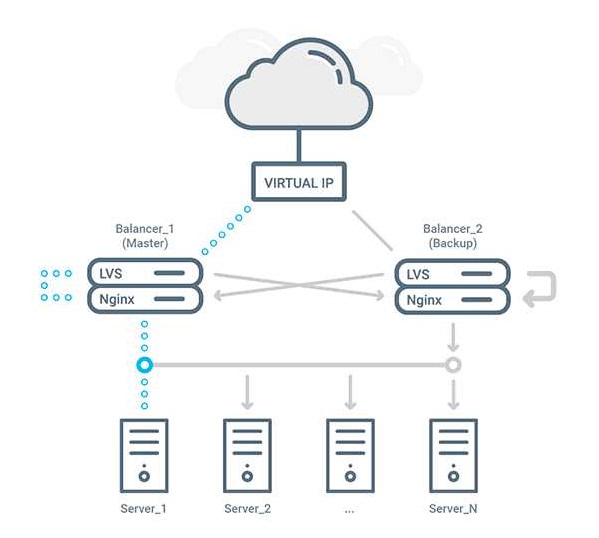
Одним из главных принципов является дублирование критически важных компонентов. Это означает, что каждая важная часть системы имеет резервную копию, которая может автоматически вступить в действие в случае отказа основной. Дублирование может касаться как серверного оборудования, так и сетевых устройств и хранилищ данных. Такой подход значительно повышает вероятность бесперебойной работы всей системы.
Следующим важным аспектом является балансировка нагрузки. Распределение задач между несколькими серверами позволяет равномерно использовать ресурсы и избегать перегрузок, которые могут привести к сбоям. Балансировка может осуществляться как на уровне аппаратных средств, так и на уровне программного обеспечения, обеспечивая оптимальную работу всех узлов системы.
Немаловажную роль играет мониторинг и диагностика. Регулярное отслеживание состояния всех компонентов позволяет выявлять потенциальные проблемы на ранних стадиях и предпринимать меры по их устранению до того, как они станут критическими. Современные системы мониторинга способны автоматически уведомлять администраторов о любых отклонениях в работе и даже предлагать возможные решения.
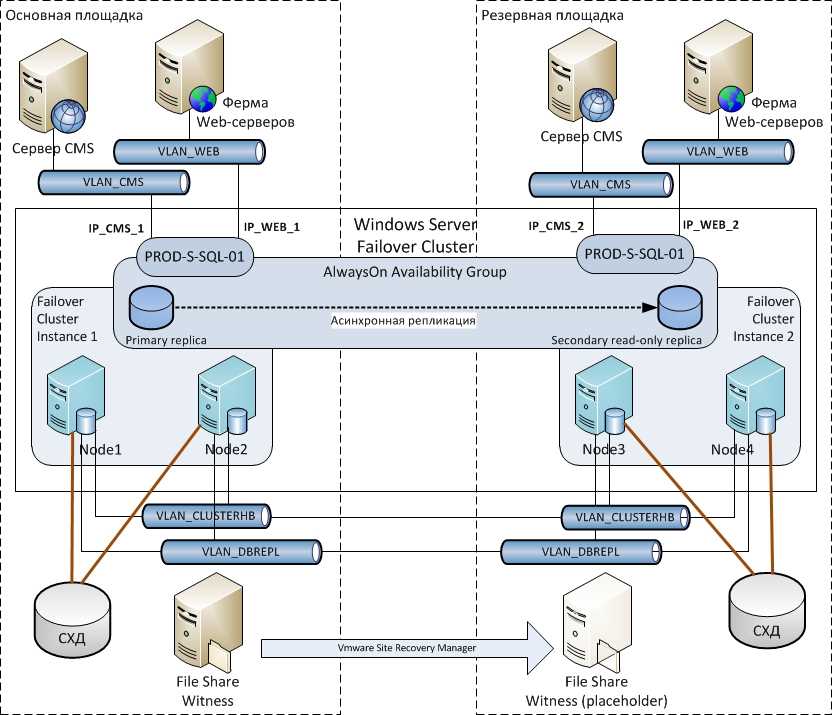
Кроме того, необходимо учитывать возможность масштабирования. Система должна быть готова к увеличению нагрузки и расширению без значительных перебоев в работе. Гибкость и адаптивность являются ключевыми характеристиками, которые позволяют системе быстро адаптироваться к изменяющимся условиям и требованиям.
Важным элементом обеспечения устойчивости также является планирование и тестирование аварийного восстановления. Регулярные тренировки и симуляции сценариев сбоев помогают убедиться в готовности системы и персонала к действиям в случае реальной чрезвычайной ситуации. Заблаговременная подготовка позволяет минимизировать потери данных и времени в случае реальных инцидентов.
Таким образом, следование основным принципам отказоустойчивости обеспечивает высокую надежность и непрерывность работы серверных систем, что является залогом стабильности и безопасности информационных технологий.
Технологии для построения кластеров
Создание системы, способной работать эффективно и надежно, требует применения современных технологий. Современные решения позволяют объединять несколько серверов в единую вычислительную инфраструктуру, обеспечивая высокую производительность и гибкость. Рассмотрим основные технологии и подходы, которые используются для построения таких объединений.
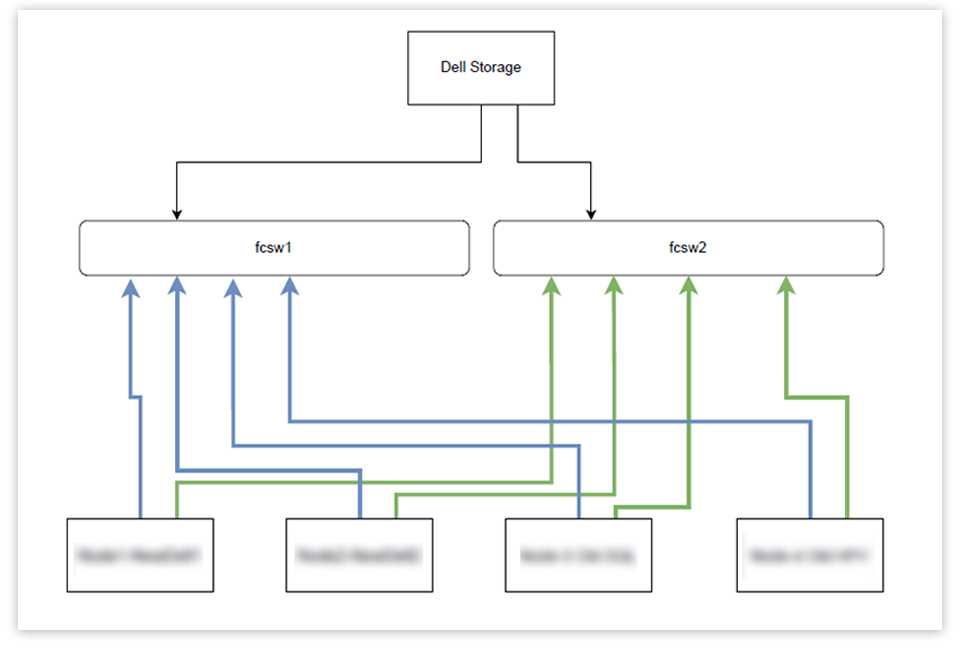
Виртуализация – одна из ключевых технологий, используемых для объединения множества физических серверов в единую виртуальную среду. Она позволяет запускать несколько виртуальных машин на одном физическом сервере, что способствует более рациональному использованию ресурсов и упрощению управления инфраструктурой. Виртуальные машины могут быть легко перемещены между физическими узлами, что обеспечивает гибкость и масштабируемость.
Контейнеризация – еще один важный подход, позволяющий изолировать приложения в контейнерах. Контейнеры обеспечивают легковесную и портативную среду для приложений, что позволяет быстро разворачивать и масштабировать сервисы. Популярные инструменты, такие как Docker и Kubernetes, активно используются для управления контейнеризованными приложениями в различных средах.
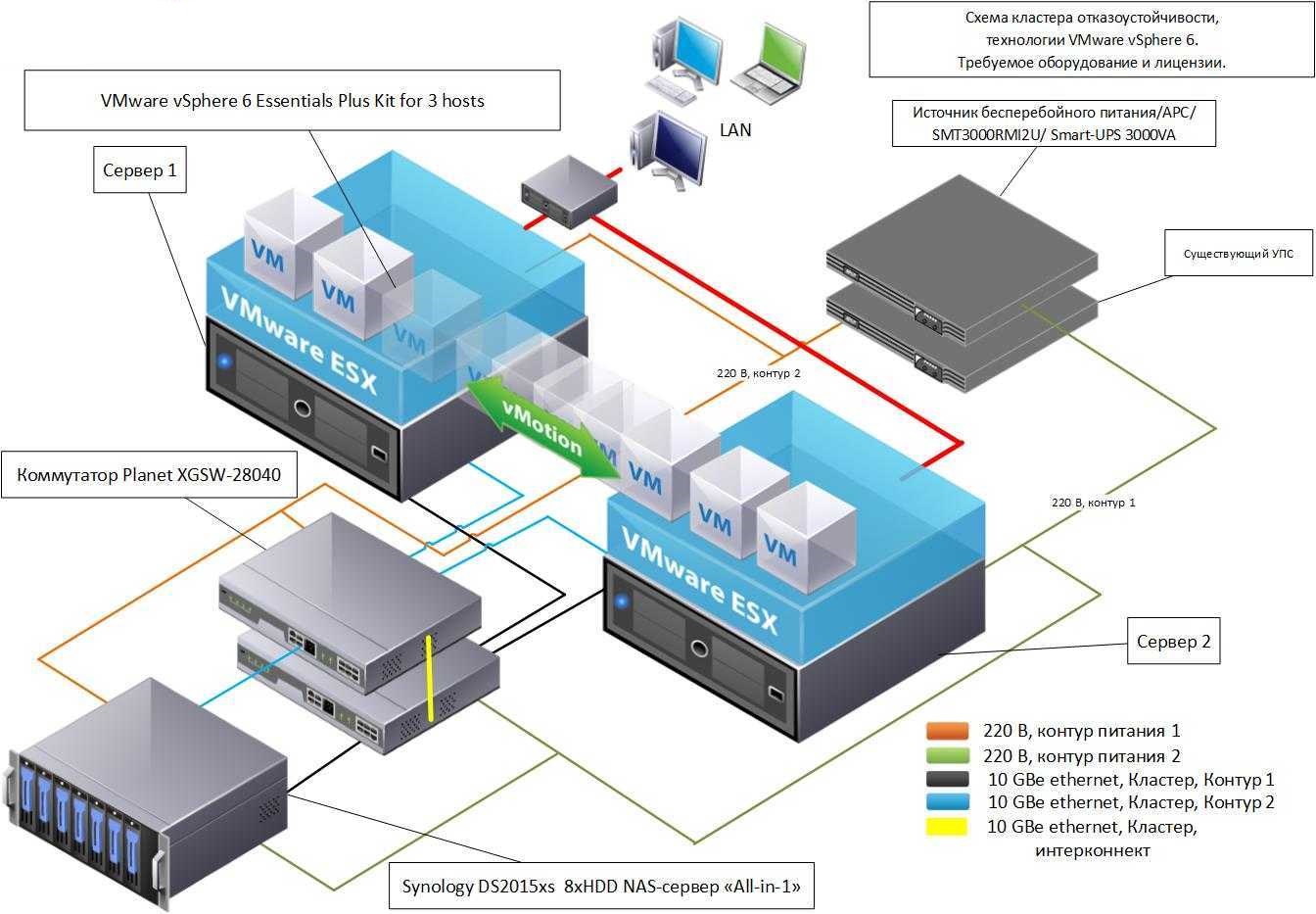
Балансировка нагрузки играет важную роль в распределении задач между серверами. Эта технология позволяет равномерно распределять запросы пользователей между доступными узлами, что предотвращает перегрузку отдельных серверов и обеспечивает равномерное использование ресурсов. Балансировщики нагрузки могут работать на различных уровнях, от сетевого до приложений, обеспечивая оптимальное распределение трафика.
Сетевые технологии также важны для объединения серверов в единую инфраструктуру. Высокоскоростные сети и коммутаторы обеспечивают быструю и надежную передачу данных между узлами, что является ключевым фактором для эффективного функционирования системы. Использование современных протоколов и сетевых решений позволяет минимизировать задержки и увеличить пропускную способность.
Современные технологии, такие как виртуализация, контейнеризация, балансировка нагрузки и передовые сетевые решения, являются основными инструментами для построения высокопроизводительных и надежных объединений серверов. Они позволяют создать гибкую и масштабируемую инфраструктуру, способную справляться с высокими нагрузками и изменяющимися требованиями пользователей.
Обзор архитектурных решений
Разработка и внедрение высоконадёжных систем требуют тщательного подхода к проектированию архитектуры. В данном разделе рассмотрим различные способы организации компонентов, обеспечивающих стабильную работу приложений и сервисов, несмотря на возможные сбои в их отдельных частях.
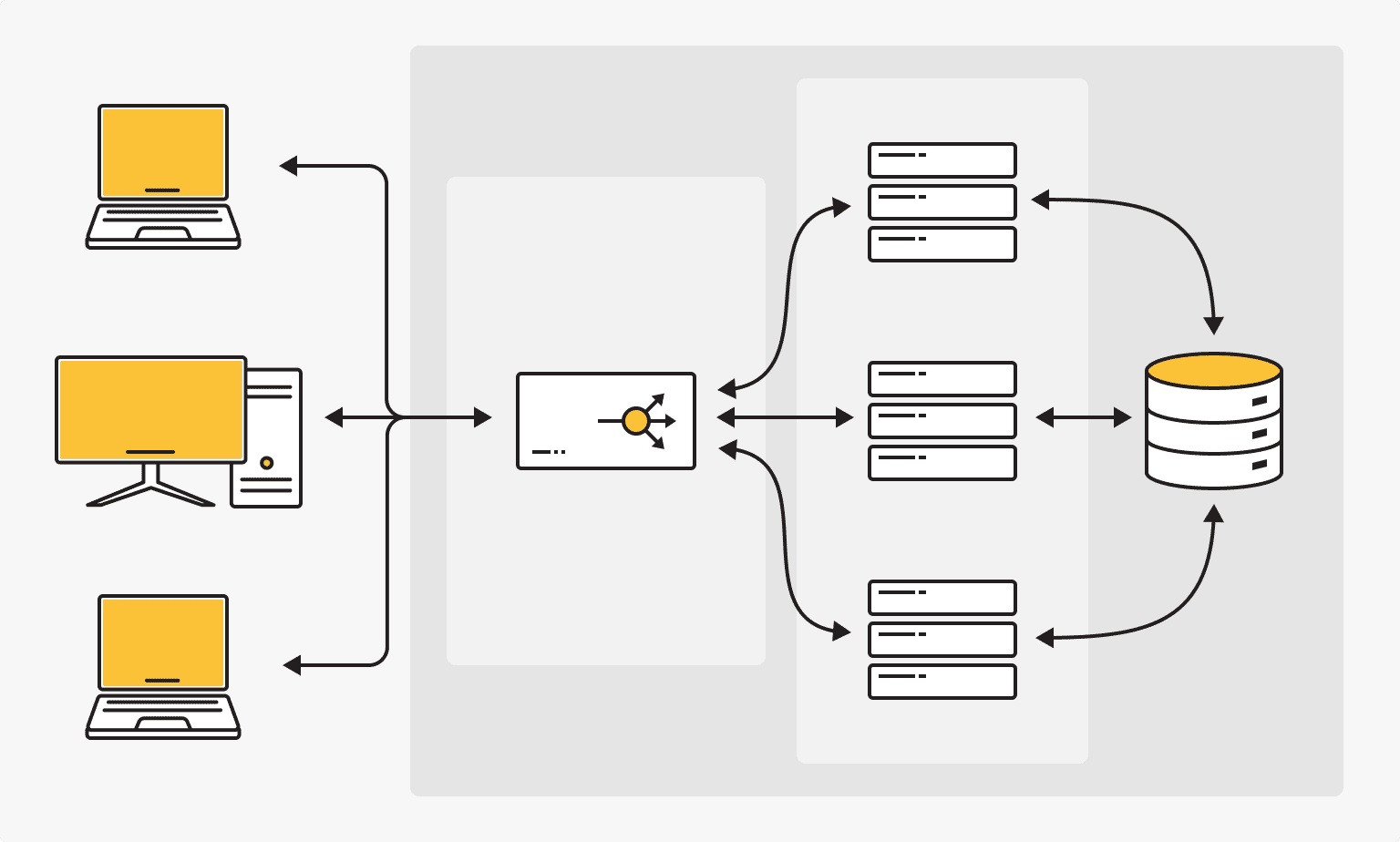
Существует множество методов и стратегий, позволяющих повысить надёжность и доступность распределённых систем. Они варьируются от использования дублирующих механизмов до интеграции сложных алгоритмов балансировки нагрузки. Рассмотрим основные подходы, применяемые для достижения устойчивости в функционировании современных информационных систем.
Архитектурное решение | Описание |
Резервирование узлов | Основной подход, предполагающий наличие дополнительных серверов, которые могут взять на себя выполнение задач в случае отказа основных компонентов. |
Горизонтальное масштабирование | Расширение системы за счёт добавления новых серверов. Такой подход улучшает производительность и устойчивость к сбоям за счёт распределения нагрузки между большим числом узлов. |
Балансировка нагрузки | Использование специальных механизмов для распределения входящих запросов между несколькими серверами, что помогает предотвратить перегрузки и обеспечить равномерное использование ресурсов. |
Репликация данных | Создание копий данных на различных узлах системы, что позволяет избежать потери информации в случае выхода из строя одного из серверов и обеспечивает постоянный доступ к данным. |
Автоматическое восстановление | Интеграция механизмов автоматического перезапуска или замены неисправных компонентов без вмешательства оператора, что ускоряет процесс восстановления работоспособности системы. |
Мониторинг и управление кластерами
Мониторинг вычислительных узлов включает в себя сбор и анализ данных о состоянии систем, их загрузке, производительности и наличии ошибок. Для этих целей используются специализированные инструменты и программные решения, которые предоставляют администраторам полную картину происходящего. Такие системы часто включают в себя средства визуализации данных, что позволяет в реальном времени отслеживать состояние всех узлов.
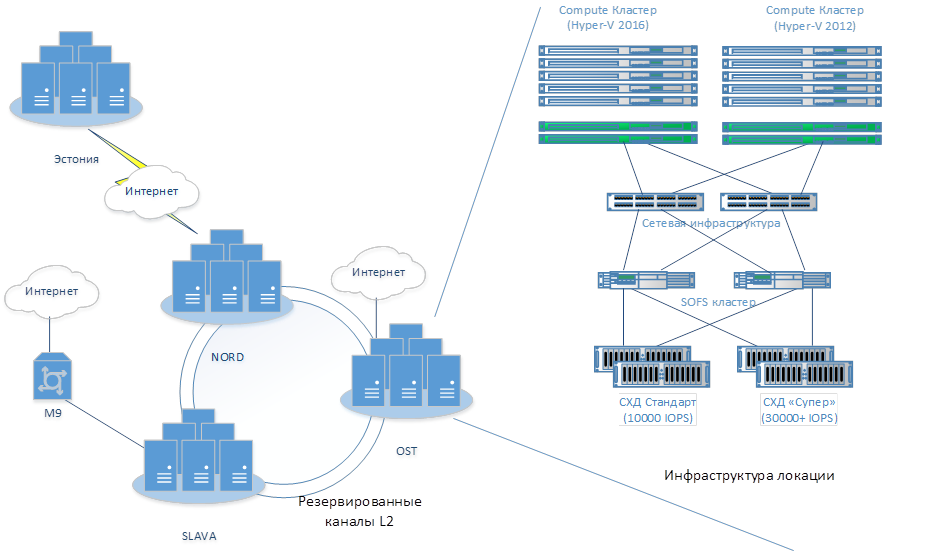
Регулярное наблюдение за состоянием инфраструктуры помогает оперативно выявлять проблемы, предотвращать сбои и минимизировать время простоя. Системы мониторинга часто обладают функциями автоматического уведомления, что позволяет мгновенно информировать ответственных лиц о возникших неполадках и инициировать процессы восстановления.
Управление вычислительными ресурсами включает в себя множество задач, таких как распределение нагрузки между узлами, обновление программного обеспечения, управление конфигурациями и обеспечение безопасности. Для эффективного управления необходимы инструменты, которые позволяют автоматизировать рутинные процессы и обеспечивать гибкость в изменяющихся условиях. Это достигается с помощью оркестрации, которая координирует действия различных компонентов системы и обеспечивает их слаженную работу.
Одним из важнейших аспектов управления является планирование ресурсов. Это включает в себя прогнозирование потребностей в вычислительных мощностях, оптимизацию использования текущих ресурсов и планирование расширений. Прогнозирование основывается на анализе исторических данных и текущих трендов, что позволяет избежать перегрузок и обеспечивать бесперебойную работу.
Наконец, следует отметить важность обучения и подготовки персонала, ответственного за управление системами. Современные технологии требуют постоянного повышения квалификации, чтобы эффективно использовать все возможности, которые предоставляют инструменты мониторинга и управления. Внедрение лучших практик и стандартов помогает создавать надежные и устойчивые системы, способные справляться с любыми вызовами.
Резервное копирование и восстановление
В первую очередь необходимо организовать регулярное создание резервных копий. Это может включать как полное копирование всей информации, так и инкрементные или дифференциальные методы, которые позволяют экономить ресурсы и время. Важно учитывать частоту и объем копируемых данных, чтобы выбрать оптимальную стратегию.
Преимущества отказоустойчивых серверов
В современных условиях информационные системы должны обеспечивать непрерывность работы и доступность данных. Отказоустойчивые серверы играют ключевую роль в обеспечении надежности и бесперебойной работы приложений и сервисов. Рассмотрим основные преимущества использования таких серверов.
Преимущество | Описание |
Высокая доступность | Обеспечение постоянного доступа к данным и сервисам даже при возникновении аппаратных сбоев или отказов. |
Устойчивость к сбоям | Системы продолжают работать в штатном режиме при отказе отдельных компонентов, минимизируя влияние на пользователей. |
Масштабируемость | Возможность добавления новых ресурсов и серверов без значительных изменений в инфраструктуре, что позволяет гибко реагировать на рост нагрузки. |
Непрерывность обслуживания | Поддержание работы сервисов и приложений даже в период проведения профилактических или ремонтных работ. |
Экономия времени и ресурсов | Снижение затрат на устранение неполадок и восстановление работы системы благодаря автоматизации и мониторингу состояния серверов. |
Использование отказоустойчивых серверов позволяет организациям минимизировать риски, связанные с потерей данных и простоем сервисов, что способствует повышению уровня доверия со стороны клиентов и партнеров. Это становится особенно важным в условиях высокой конкуренции и требований к качеству обслуживания.
Вопрос-ответ
Что такое отказоустойчивый кластер и зачем он нужен?
Отказоустойчивый кластер представляет собой группу серверов, которые работают вместе таким образом, что, если один из них выходит из строя, остальные продолжают обеспечивать работу приложений и сервисов. Основная цель использования отказоустойчивых кластеров — обеспечить непрерывность бизнеса и минимизировать простои, которые могут возникнуть из-за аппаратных или программных сбоев. Это особенно важно для критически важных систем, таких как банковские приложения, системы управления запасами или онлайн-магазины, где даже кратковременные перерывы могут привести к значительным убыткам.
Какие преимущества и недостатки есть у отказоустойчивых кластеров?
Отказоустойчивые кластеры обладают рядом преимуществ и недостатков. Преимущества. Высокая доступность – обеспечивают непрерывность работы сервисов даже при выходе из строя одного или нескольких узлов. Масштабируемость – легко добавлять новые узлы для увеличения вычислительных мощностей и хранения данных. Распределение нагрузки – эффективное использование ресурсов за счет равномерного распределения запросов. Недостатки. Высокая стоимость – требуют значительных инвестиций в оборудование и программное обеспечение. Сложность управления – настройка и управление кластером требуют специальных знаний и навыков. Риски некорректной настройки – ошибки в конфигурации могут привести к ухудшению производительности или даже сбоям всей системы.
Что такое отказоустойчивый кластер серверов?
Отказоустойчивый кластер серверов – это группа серверов, спроектированная для обеспечения непрерывной работы системы даже при отказе одного или нескольких компонентов. В таком кластере используются специальные механизмы, такие как репликация данных, механизмы обнаружения отказов и автоматического восстановления, чтобы минимизировать простои и обеспечить непрерывную доступность сервисов.
Как работает схема отказоустойчивого кластера?
Схема отказоустойчивого кластера основана на распределении нагрузки и резервировании ресурсов между узлами кластера. Обычно в такой схеме используется дублирование данных на нескольких серверах, чтобы в случае отказа одного сервера данные оставались доступными на других. Также применяются механизмы обнаружения отказов, которые автоматически перенаправляют трафик на работающие серверы, минимизируя простои и обеспечивая непрерывную работу системы.
Читайте также:
- Создание отказоустойчивого кластера в 1С:Предприятие
- Отказоустойчивый кластер Windows для повышения надежности систем
- Отказоустойчивый кластер Hyper V для повышения надежности систем
- Создание отказоустойчивого кластера MS SQL для обеспечения надежности и доступности данных
- Создание отказоустойчивого кластера в Windows Server 2019
- Файловый отказоустойчивый кластер для повышения надежности и доступности данных
- Отказоустойчивые системы: ключевой элемент безопасности и надежности