Резервирование сетевого оборудования для повышения надежности и отказоустойчивости
Содержание:
- Роль резервирования в сетевых инфраструктурах
- Основные стратегии обеспечения отказоустойчивости
- Преимущества использования горячих и холодных резервов
- Методы минимизации простоев при сбоях оборудования
- Влияние резервирования на безопасность сети
- Как выбрать подходящее оборудование для резервирования
- Вопрос-ответ

Для поддержания высокой производительности необходимо предусмотреть специальные решения, позволяющие оперативно восстанавливать функционал при возникновении сбоев. Это создает основу для эффективной защиты от неожиданностей, будь то сбои в программной или аппаратной части. Важно учитывать разные аспекты, от методов дублирования до стратегии восстановления работоспособности.
Правильно спроектированные структуры позволяют значительно уменьшить риск непредвиденных остановок работы. Такая архитектура обеспечивает высокий уровень отказоустойчивости, а также повышает общую безопасность информационных потоков. Внедрение таких решений требует учета всех потенциальных уязвимостей и возможности оперативного реагирования на возникающие проблемы.
Роль резервирования в сетевых инфраструктурах
Резервирование в сетевых инфраструктурах играет ключевую роль в обеспечении надёжности, доступности и непрерывности работы сети. Это практика создания избыточных элементов в сети – от резервных каналов связи до дублирующих серверов и маршрутизаторов, чтобы предотвратить сбои и минимизировать их последствия. Основная цель резервирования – обеспечить бесперебойное функционирование сети даже в случае отказа одного или нескольких компонентов.

Одним из главных аспектов резервирования является защита от аппаратных сбоев. Сетевые устройства, такие как маршрутизаторы, коммутаторы или серверы, могут выйти из строя по разным причинам, включая перегрузку, аппаратные неисправности или сбои в электропитании. Если в сети настроены резервные устройства, они могут автоматически заменить отказавшие, обеспечивая стабильную работу. Этот процесс называется отказоустойчивостью, и он критически важен для компаний, где простои сети могут привести к значительным потерям.
Резервирование также касается каналов передачи данных. Если основной канал связи оказывается недоступен, например, из-за технических работ или аварии, резервный канал обеспечивает продолжение передачи данных. Это особенно актуально для глобальных и распределённых сетей, где утрата соединения с одним из узлов может нарушить коммуникацию в целом.
Роль резервирования особенно важна для центров обработки данных (ЦОД) и облачных инфраструктур, где простои могут повлиять на большое количество пользователей. В таких системах используются стратегии резервирования, такие как RAID для хранения данных, а также механизмы резервного копирования и восстановления информации. Это позволяет защитить данные от потери, а также гарантирует их доступность в случае сбоя оборудования или программного обеспечения.
Кроме того, резервирование необходимо для защиты от сбоев в электроснабжении. Использование источников бесперебойного питания (UPS) и резервных генераторов помогает избежать простоев при краткосрочных отключениях электроэнергии.
Важным элементом резервирования в сетевых инфраструктурах является мониторинг и автоматическое переключение на резервные компоненты при возникновении сбоев. Технологии динамической маршрутизации и протоколы, такие как HSRP (Hot Standby Router Protocol) или VRRP (Virtual Router Redundancy Protocol), обеспечивают автоматическое управление трафиком и переключение на резервные маршрутизаторы или каналы в случае необходимости
Основные стратегии обеспечения отказоустойчивости
Отказоустойчивость – это способность системы продолжать функционировать даже в случае отказа одного или нескольких ее компонентов. Для обеспечения высокой надёжности сетевых и вычислительных систем используются различные стратегии отказоустойчивости, каждая из которых направлена на минимизацию простоев и защиту от сбоев. Вот основные из них:
1. Резервирование оборудования и каналов связи
Одной из самых распространенных стратегий является дублирование ключевых элементов системы. Это может быть резервное оборудование (маршрутизаторы, коммутаторы, серверы) или резервные каналы связи. В случае отказа основного устройства или канала резервный компонент автоматически берёт на себя его функции. Для этого используются протоколы, такие как HSRP (Hot Standby Router Protocol) или VRRP (Virtual Router Redundancy Protocol), которые обеспечивают автоматическое переключение на резервный маршрутизатор в случае выхода из строя основного.
2. RAID-массивы для хранения данных
RAID (Redundant Array of Independent Disks) – это технология резервирования данных на жёстких дисках, которая обеспечивает их сохранность даже в случае выхода из строя одного или нескольких дисков. Существует несколько уровней RAID, обеспечивающих как ускорение работы системы (RAID 0), так и отказоустойчивость за счет зеркалирования данных (RAID 1) или использования контрольных сумм для восстановления информации (RAID 5, RAID 6).
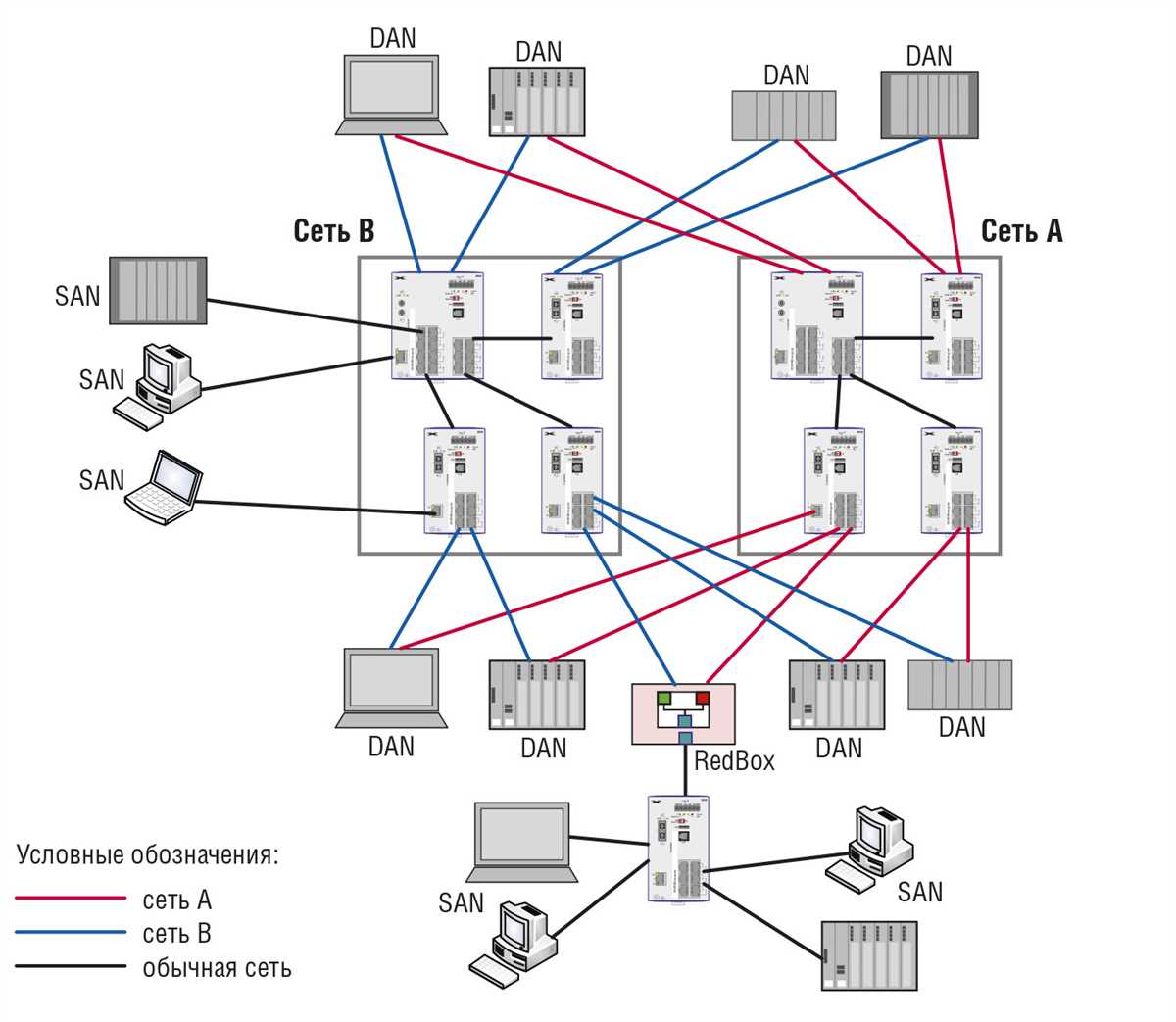
3. Кластеризация серверов
Кластеризация – это объединение нескольких серверов в единый "кластер", где каждый сервер дублирует функции других. Если один сервер выходит из строя, его задачи автоматически перераспределяются между другими серверами кластера, что предотвращает простои. Эта стратегия особенно эффективна для критически важных приложений и сервисов, таких как базы данных или веб-сайты с высокой нагрузкой. Кластеры могут быть активными (где все серверы работают одновременно) или пассивными (где резервные серверы включаются только в случае отказа).
4. Балансировка нагрузки
Балансировка нагрузки – это стратегия распределения трафика или вычислительных задач между несколькими серверами или устройствами, чтобы избежать перегрузки одного элемента системы. Если один сервер перегружен или выходит из строя, трафик автоматически направляется на другие серверы. Это не только повышает отказоустойчивость, но и улучшает общую производительность системы. Для балансировки нагрузки могут использоваться как аппаратные, так и программные решения.
5. Репликация данных
Репликация – это создание копий данных на нескольких серверах или в разных географических зонах. В случае сбоя или потери данных на основном сервере можно мгновенно переключиться на резервный, сохранив доступ к информации. Репликация может быть синхронной (данные обновляются одновременно на всех серверах) или асинхронной (данные обновляются с задержкой, что может быть полезно для работы с географически распределёнными серверами).
6. Использование виртуальных машин (VM) и контейнеров
Виртуализация позволяет создавать копии приложений и операционных систем в виде виртуальных машин или контейнеров. В случае сбоя физического сервера виртуальные машины могут быть быстро перемещены на другой сервер без значительных простоев. Контейнеры, такие как Docker или Kubernetes, позволяют легко разворачивать приложения в различных средах, что упрощает управление отказоустойчивостью и ускоряет восстановление после сбоя.
7. Облачные решения
Многие компании переходят на использование облачных платформ для повышения отказоустойчивости. Облако предоставляет множество встроенных механизмов для резервирования, балансировки нагрузки и репликации данных. Облачные провайдеры, такие как AWS, Microsoft Azure или Google Cloud, предлагают сервисы, которые автоматически распределяют данные и вычислительные ресурсы по нескольким зонам доступности, что защищает от сбоев в одном из центров обработки данных.
В совокупности эти стратегии обеспечивают высокую доступность и надёжность сетевых и вычислительных систем, позволяя бизнесам избегать простоев и потерь данных, а также быстро восстанавливаться после сбоев.
Преимущества использования горячих и холодных резервов
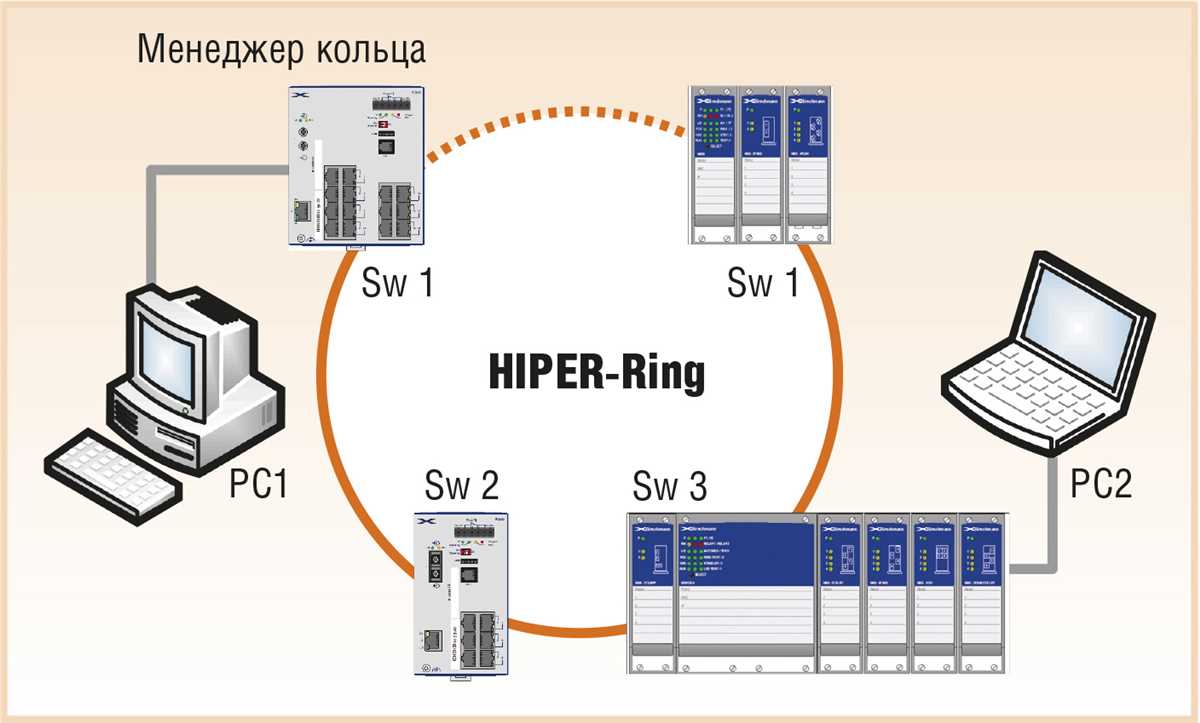
Горячий резерв обеспечивает мгновенную готовность к работе. При его использовании переход на запасной элемент происходит автоматически, что минимизирует время простоя. Это особенно важно для критически важных систем, где даже кратковременное прекращение работы может привести к серьезным последствиям.
Холодный резерв требует больше времени для активации, так как запасной элемент остается отключенным до тех пор, пока не понадобится. Однако этот способ чаще всего используется для менее чувствительных систем, где скорость переключения не является критичным параметром, но важен минимальный расход ресурсов.
В целом, правильное сочетание горячих и холодных резервов позволяет найти баланс между затратами и скоростью восстановления. Выбор подходящего метода зависит от требований к системе, бюджета и важности обеспечения бесперебойной работы.
Методы минимизации простоев при сбоях оборудования
Минимизация простоев при сбоях оборудования – важная задача для поддержания стабильной работы сети и бизнеса в целом. Существуют различные методы, которые помогают снизить время простоя, предотвращать сбои и обеспечивать быстрое восстановление работоспособности системы. Вот ключевые из них:
1. Резервирование оборудования и дублирование компонентов
Один из наиболее эффективных способов минимизации простоев – это использование резервных компонентов. В сетевой инфраструктуре это может быть дублирование критически важных устройств, таких как маршрутизаторы, коммутаторы, серверы и каналы связи. В случае сбоя основного устройства резервный компонент моментально вступает в работу, предотвращая прерывание сервиса. Это достигается с помощью таких технологий, как HSRP (Hot Standby Router Protocol) или VRRP (Virtual Router Redundancy Protocol), которые обеспечивают плавное переключение между устройствами.

2. Использование кластерных систем и балансировка нагрузки
Кластеризация серверов или приложений позволяет объединять несколько физических или виртуальных серверов в одну систему, которая может автоматически перераспределять задачи в случае выхода из строя одного из узлов. Балансировка нагрузки помогает равномерно распределять трафик между несколькими серверами, что снижает риск перегрузки и возможного сбоя. При этом, если один сервер выходит из строя, другие продолжают работу, и трафик автоматически перенаправляется на них.
3. Репликация данных и систем
Репликация – это процесс создания копий данных или систем на нескольких серверах. Это позволяет мгновенно переключиться на резервный сервер в случае сбоя основного. Репликация может быть синхронной (данные обновляются одновременно на всех серверах) или асинхронной (с задержкой). Применение репликации в критических приложениях и базах данных гарантирует, что даже при серьёзных сбоях или авариях данные останутся доступными.
4. Резервное копирование и план восстановления после сбоев
Создание регулярных резервных копий данных и разработка плана восстановления после сбоев (Disaster Recovery Plan) помогает быстро вернуть систему в рабочее состояние после аварии. Резервные копии должны храниться как локально, так и в удалённых местах для защиты от локальных аварий, таких как пожары или наводнения. Важно также регулярно тестировать план восстановления, чтобы убедиться, что он работает корректно и позволяет минимизировать время простоя.
5. Виртуализация и контейнеризация
Виртуальные машины и контейнеры, такие как Docker или Kubernetes, позволяют легко мигрировать приложения и сервисы между различными серверами и средами. В случае сбоя физического сервера виртуальные машины можно быстро перенести на другое оборудование, не прерывая работу. Контейнеризация позволяет развертывать приложения в стандартизированной среде, что также упрощает процесс восстановления после сбоя.
6. Источники бесперебойного питания (UPS) и резервные генераторы
Один из частых факторов сбоев – это потеря электропитания. Источники бесперебойного питания (UPS) могут защитить оборудование от кратковременных отключений электричества и позволить безопасно завершить работу в случае длительного сбоя. Для более длительных сбоев можно использовать резервные генераторы, которые поддерживают работу оборудования в течение нескольких часов или дней, в зависимости от ситуации.
7. Мониторинг и предиктивное обслуживание
Постоянный мониторинг сетевой инфраструктуры и оборудования с помощью специализированных инструментов помогает заранее выявлять потенциальные проблемы, такие как перегрузка, перегрев или ухудшение состояния оборудования. Предиктивное обслуживание позволяет устранять проблемы до того, как они вызовут сбой. Например, замена устройства или компонента может быть произведена до его полного выхода из строя, что существенно сокращает риск простоев.
Эти методы помогают минимизировать простои и обеспечивают надёжную работу системы, даже если происходит сбой оборудования или программного обеспечения. Внедрение резервирования, кластеризации и мониторинга, а также подготовка чёткого плана восстановления после сбоев позволяют снизить риски и быстро вернуть систему в рабочее состояние.
Влияние резервирования на безопасность сети
Продуманный подход к архитектуре инфраструктуры позволяет повысить уровень защищенности от разнообразных угроз и отказов. Это достигается за счёт создания дополнительных путей и механизмов, которые обеспечивают бесперебойную работу системы в случае возникновения непредвиденных ситуаций. Таким образом, улучшается как общая надежность, так и способность противостоять внешним и внутренним угрозам.
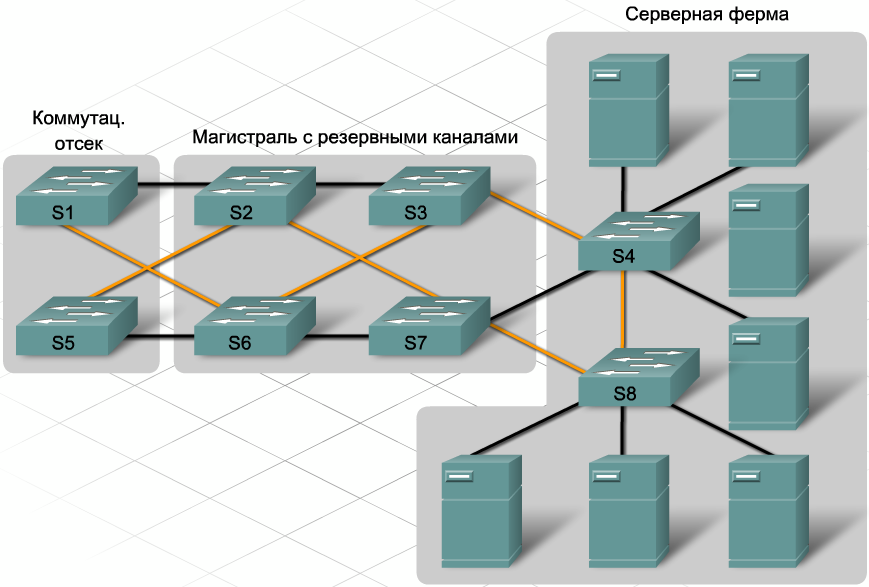
Основной эффектзаключается в повышении устойчивости к сбоям, которые могут возникнуть по различным причинам – от технических проблем до целенаправленных атак. Если один элемент выходит из строя, альтернативные механизмы вступают в действие, предотвращая возможные нарушения или минимизируя их последствия.
Кибератаки, такие как DDoS-атаки или заражение вирусами, могут вывести из строя важные сетевые компоненты. Резервирование критических элементов инфраструктуры (серверов, маршрутизаторов, коммутаторов) помогает поддерживать работоспособность сети даже при атаке. Системы автоматически переключаются на резервные каналы или оборудование, не давая злоумышленникам парализовать всю сеть.
В случае серьезных инцидентов, таких как хакерские атаки или сбои в работе оборудования, важно быстро восстановить работу сети. Резервирование позволяет мгновенно переключиться на дублирующие системы, что сокращает время простоя и снижает последствия инцидента. Это особенно важно для критически важных сервисов, где даже короткий простой может привести к финансовым потерям или угрозе безопасности.
Резервирование в сети помогает поддерживать ее непрерывную работу даже в случае сбоев. Это критически важно для организаций, работающих с конфиденциальной информацией, такими как банки, государственные учреждения или медицинские организации, где утечка данных или простой могут привести к серьёзным последствиям. Надёжное резервирование минимизирует риски отказа и повышает общую безопасность сети.
Как выбрать подходящее оборудование для резервирования
Для обеспечения надежной работы системы важно уделить внимание выбору компонентов, которые будут поддерживать её функционирование в случае сбоев. В зависимости от масштабов и специфики проекта, правильный выбор аппаратных средств может значительно повысить эффективность работы и предотвратить неполадки.
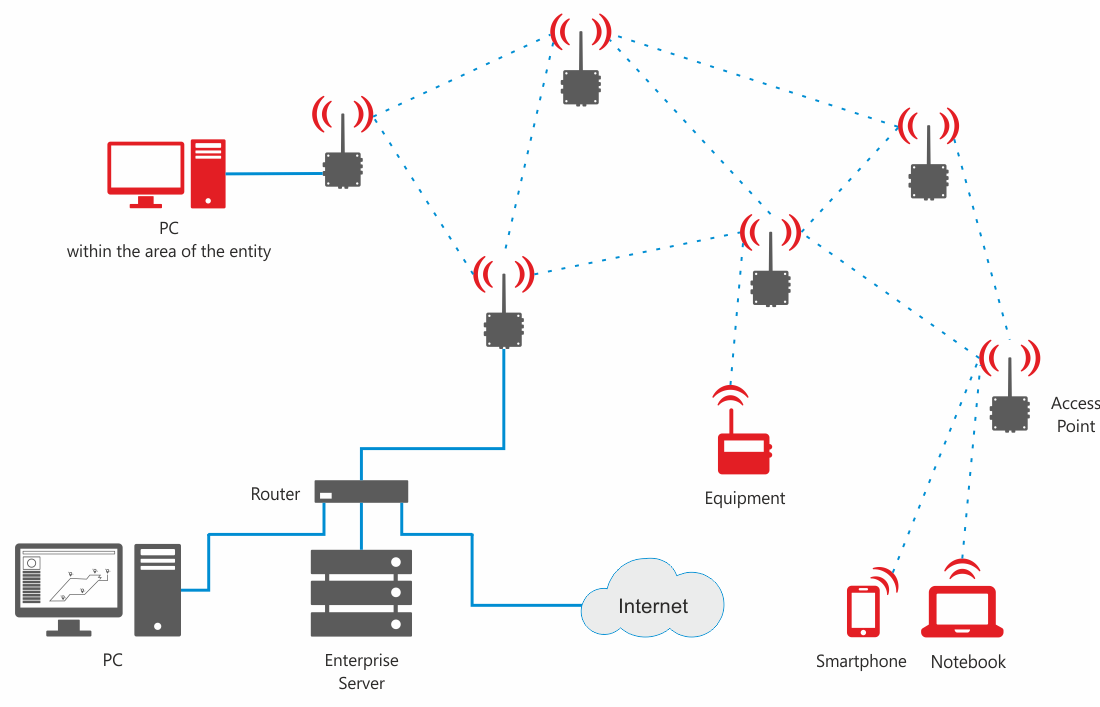
Первый шаг – оценить требования к нагрузке и объемам данных, с которыми будет работать система. Это поможет понять, насколько мощными и гибкими должны быть компоненты. Необходимо учитывать как текущие потребности, так и возможные будущие расширения.
Следующим важным моментом является совместимость компонентов с существующей инфраструктурой. Важно, чтобы все части системы могли взаимодействовать друг с другом без проблем, обеспечивая быструю и беспрерывную передачу данных.
Также следует обратить внимание на уровень устойчивости к отказам. Чем выше этот показатель, тем меньше вероятность того, что один сбой приведет к остановке всей системы. Это особенно важно для критически важных сервисов и приложений.
Наконец, стоит учитывать простоту обслуживания и наличие поддержки от производителя. Чем проще процесс диагностики и восстановления работы, тем быстрее можно устранить неисправности и вернуться к нормальному функционированию системы.
Вопрос-ответ
Что такое резервирование сетевого оборудования и зачем оно нужно?
Резервирование сетевого оборудования – это процесс создания дополнительных путей для передачи данных и установки дублирующих устройств для повышения надежности сети. Основная цель резервирования – минимизировать время простоя и предотвратить сбои в работе сети. В случае выхода из строя одного элемента (например, маршрутизатора или коммутатора), резервные устройства или каналы автоматически берут на себя функции основного оборудования, что обеспечивает непрерывность работы сети.
Какие типы резервирования сетевого оборудования существуют?
Существует несколько типов резервирования сетевого оборудования. Во-первых, это резервирование на уровне оборудования, когда дублируются физические устройства, такие как маршрутизаторы, коммутаторы или сервера. Во-вторых, это резервирование на уровне каналов передачи данных – использование нескольких каналов связи для повышения устойчивости сети. Также существует программное резервирование, когда используется виртуализация и специальные протоколы, такие как VRRP или HSRP, для автоматического переключения на резервные ресурсы в случае сбоя.
Какие протоколы используются для резервирования сетевого оборудования?
Наиболее часто используемые протоколы для резервирования сетевого оборудования включают VRRP (Virtual Router Redundancy Protocol) и HSRP (Hot Standby Router Protocol). Эти протоколы обеспечивают автоматическое переключение на резервное оборудование, если основное выходит из строя. VRRP используется для обеспечения резервирования маршрутизаторов, создавая виртуальный маршрутизатор, которому назначается IP-адрес, к которому обращаются клиенты. HSRP – это проприетарный протокол Cisco, который работает аналогично VRRP, обеспечивая беспрерывную работу сети при отказе устройства.
Какие факторы следует учитывать при планировании резервирования сетевого оборудования?
При планировании резервирования сетевого оборудования необходимо учитывать несколько важных факторов. Во-первых, это критичность приложения или сервиса: чем выше его значимость для бизнеса, тем более надежной должна быть система резервирования. Во-вторых, необходимо учесть бюджетные ограничения, так как покупка дублирующих устройств и каналов может быть дорогостоящей. Также важно учитывать совместимость оборудования и программного обеспечения, а также использовать правильные протоколы для автоматического переключения на резервные ресурсы. Не менее важно учесть и скорость восстановления после сбоя, чтобы минимизировать время простоя.
Читайте также:
- Что делать, если сервис временно недоступен, и как быстро решить проблему
- Угрозы для сетевого оборудования и методы защиты
- Как выбрать сетевое оборудование для вашего бизнеса
- Настройка активного сетевого оборудования для оптимизации сети
- Правила эффективного обслуживания сетевого оборудования
- Основные уязвимости сетевого оборудования и методы их устранения
- Отключение сетевого оборудования: что это значит и как это исправить
- Сетевые проблемы безопасности оборудования и возможные угрозы
- Все о трафике Wi-Fi роутера